Effarant et pourtant, nous le savons, ce n’est pas une surprise mais, au delà des « espions » connus il y a les moins connus. Tout ce que vous écrivez, visitez, consommez, achetez, ainsi que vos états d’âme, votre mal-être, vos maladies, vos questions, l’état de vos finances, tout est collecté, analysé, épluché. Si vous avez besoin d’un crédit et qu’il vous est refusé, posez vous des questions.
Vous croyez tout savoir déjà sur l’exploitation de nos données personnelles ? Parcourez plutôt quelques paragraphes de ce très vaste dossier…
Il s’agit du remarquable travail d’enquête procuré par Craked Labs, une organisation sans but lucratif qui se caractérise ainsi :
… un institut de recherche indépendant et un laboratoire de création basé à Vienne, en Autriche. Il étudie les impacts socioculturels des technologies de l’information et développe des innovations sociales dans le domaine de la culture numérique.
… Il a été créé en 2012 pour développer l’utilisation participative des technologies de l’information et de la communication, ainsi que le libre accès au savoir et à l’information – indépendamment des intérêts commerciaux ou gouvernementaux. Cracked Labs se compose d’un réseau interdisciplinaire et international d’experts dans les domaines de la science, de la théorie, de l’activisme, de la technologie, de l’art, du design et de l’éducation et coopère avec des parties publiques et privées.
Bien sûr, vous connaissez les GAFAM omniprésents aux avant-postes pour nous engluer au point que s’en déprendre complètement est difficile… Mais connaissez-vous Acxiom et LiveRamp, Equifax, Oracle, Experian et TransUnion ? Non ? Pourtant il y a des chances qu’ils nous connaissent bien…
Il existe une industrie très rentable et très performante des données « client ».
Dans ce long article documenté et qui déploie une vaste gamme d’exemples dans tous les domaines, vous ferez connaissance avec les coulisses de cette industrie intrusive pour laquelle il semble presque impossible de « passer inaperçu », où notre personnalité devient un profil anonyme mais tellement riche de renseignements que nos nom et prénom n’ont aucun intérêt particulier.
L’article est long, vous pouvez préférer le lire à votre rythme en format .PDF (376,2 Ko)
avec les contributions de : Katharina Kopp, Patrick Urs Riechert / Illustrations de Pascale Osterwalder.
Comment des milliers d’entreprises surveillent, analysent et influencent la vie de milliards de personnes. Quels sont les principaux acteurs du pistage numérique aujourd’hui ? Que peuvent-ils déduire de nos achats, de nos appels téléphoniques, de nos recherches sur le Web, de nos Likesur Facebook ? Comment les plateformes en ligne, les entreprises technologiques et les courtiers en données font-ils pour collecter, commercialiser et exploiter nos données personnelles ?
Ces dernières années, des entreprises dans de nombreux secteurs se sont mises à surveiller, pister et suivre les gens dans pratiquement tous les aspects de leur vie. les comportements, les déplacements, les relations sociales, les centres d’intérêt, les faiblesses et les moments les plus intimes de milliards de personnes sont désormais continuellement enregistrés, évalués et analysés en temps réel. L’exploitation des données personnelles est devenue une industrie pesant plusieurs milliards de dollars. Pourtant, de ce pistage numérique omniprésent, on ne voit que la partie émergée de l’iceberg ; la majeure partie du processus se déroule dans les coulisses et reste opaque pour la plupart d’entre nous.
Ce rapport de Cracked Labs examine le fonctionnement interne et les pratiques en vigueur dans cette industrie des données personnelles. S’appuyant sur des années de recherche et sur un précédent rapport de 2016, l’enquête donne à voir la circulation cachée des données entre les entreprises. Elle cartographie la structure et l’étendue de l’écosystème numérique de pistage et de profilageet explore tout ce qui s’y rapporte : les technologies, les plateformes, les matériels ainsi que les dernières évolutions marquantes.
Le rapport complet (93 pages, en anglais) est disponible en téléchargement au format PDF, et cette publication web en présente un résumé en dix parties.
En 2007, Apple a lancé le smartphone, Facebook a atteint les 30 millions d’utilisateurs, et des entreprises de publicité en ligne ont commencé à cibler les internautes en se basant sur des données relatives à leurs préférences individuelles et leurs centres d’intérêt. Dix ans plus tard, un large ensemble d’entreprises dont le cœur de métier est les données (les data-companies ou entreprises de données en français) a émergé, on y trouve de très gros acteurs comme Facebook ou Google mais aussi des milliers d’autres entreprises, qui sans cesse, se partagent et se vendent les unes aux autres des profils numériques. Certaines entreprises ont commencé à combiner et à relier des données du web et des smartphones avec les données clients et les informations hors-ligne qu’elles avaient accumulées pendant des décennies.
La machine omniprésente de surveillance en temps réel qui a été développée pour la publicité en ligne s’étend rapidement à d’autres domaines, de la tarification à la communication politique en passant par le calcul de solvabilité et la gestion des risques. Des plateformes en ligne énormes, des entreprises de publicité numérique, des courtiers en données et des entreprises de divers secteurs peuvent maintenant identifier, trier, catégoriser, analyser, évaluer et classer les utilisateurs via les plateformes et les matériels. Chaque clic sur un site web et chaque mouvement du doigt sur un smartphone peut activer un large éventail de mécanismes de partage de données distribuées entre plusieurs entreprises, ce qui, en définitive, affecte directement les choix offerts aux gens. Le pistage numérique et le profilage, en plus de la personnalisation ne sont pas seulement utilisés pour surveiller, mais aussi pour influencer les comportements des personnes.
Vous devez vous battre pour votre vie privée, sinon vous la perdrez.
Eric Schmidt, Google/Alphabet, 2013
Analyser les individus
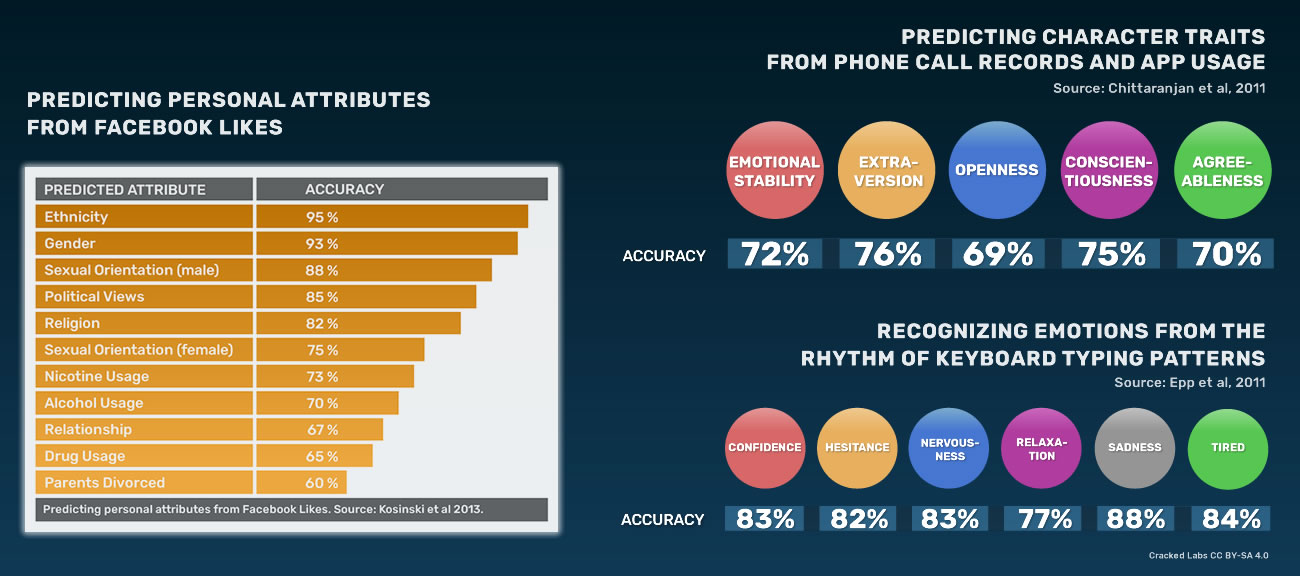
Des études scientifiques démontrent que de nombreux aspects de la personnalité des individus peuvent être déduits des données générées par des recherches sur Internet, des historiques de navigation, des comportements lors du visionnage d’une vidéo, des activités sur les médias sociaux ou des achats. Par exemple, des données personnelles sensibles telles que l’origine ethnique, les convictions religieuses ou politiques, la situation amoureuse, l’orientation sexuelle, ou l’usage d’alcool, de cigarettes ou de drogues peuvent être assez précisément déduites des Like sur Facebook d’une personne. L’analyse des profils de réseaux sociaux peut aussi prédire des traits de personnalité comme la stabilité émotionnelle, la satisfaction individuelle, l’impulsivité, la dépression et l’intérêt pour le sensationnel.
Analyser les like Facebook, les données des téléphones, et les styles de frappe au clavier
Pour plus de détails, se référer à Christl and Spiekermann 2016 (p. 14-20). Sources : Kosinski et al 2013, Chittaranjan et al 2011, Epp at al 2011.
De la même façon, il est possible de déduire certains traits de caractères d’une personne à partir de données sur les sites Web qu’elle a visités, sur les appels téléphoniques qu’elle a passés, et sur les applis qu’elle a utilisées. L’historique de navigation peut donner des informations sur la profession et le niveau d’étude. Des chercheurs canadiens ont même réussi à évaluer des états émotionnels comme la confiance, la nervosité, la tristesse ou la fatigue en analysant la façon dont on tape sur le clavier de l’ordinateur.
Analyser les individus dans la finance, les assurances et la santé
Les résultats des méthodes actuelles d’extraction et d’analyse des données reposent sur des corrélations statistiques avec un certain niveau de probabilité. Bien qu’ils soient significativement plus fiables que le hasard dans la prédiction des caractéristiques ou des traits de caractère d’un individu, ils ne sont évidemment pas toujours exacts. Néanmoins, ces méthodes sont déjà mises en œuvre pour trier, catégoriser, étiqueter, évaluer, noter et classer les personnes, non seulement dans une approche marketing mais aussi pour prendre des décisions dans des domaines riches en conséquence comme la finance, l’assurance, la santé, pour ne citer qu’eux.
L’évaluation de crédit basée sur les données de comportement numérique
Des startups comme Lenddo, Kreditech, Cignifi et ZestFinance utilisent déjà les données récoltées sur les réseaux sociaux, lors de recherches sur le web ou sur les téléphones portables pour calculer la solvabilité d’une personne sans même utiliser de données financières. D’autres se basent sur la façon dont quelqu’un va remplir un formulaire en ligne ou naviguer sur un site web, sur la grammaire et la ponctuation de ses textos, ou sur l’état de la batterie de son téléphone. Certaines entreprises incluent même des données sur les amis avec lesquels une personne est connectée sur un réseau social pour évaluer sa solvabilité.
Cignifi, qui calcule la solvabilité des clients en fonction des horaires et de la fréquence des appels téléphoniques, se présente comme « la plateforme ultime de monétisation des données pour les opérateurs de réseaux mobiles ». De grandes entreprises, notamment MasterCard, le fournisseur d’accès mobile Telefonica, les agences d’évaluation de solvabilité Experian et Equifax, ainsi que le géant chinois de la recherche web Baidu, ont commencé à nouer des partenariats avec des startups de ce genre. L’application à plus grande échelle de services de cette nature est particulièrement en croissance dans les pays du Sud, ainsi qu’auprès de groupes de population vulnérables dans d’autres régions.
Réciproquement, les données de crédit nourrissent le marketing en ligne. Sur Twitter, par exemple, les annonceurs peuvent cibler leurs publicités en fonction de la solvabilité supposée des utilisateurs de Twittersur la base des données client fournies par le courtier en données Oracle. Allant encore plus loin dans cette logique, Facebook a déposé un brevet pour une évaluation de crédit basée sur la cote de solvabilité de vos amis sur un réseau social. Personne ne sait s’ils ont l’intention de réellement mettre en application cette intégration totale des réseaux sociaux, du marketing et de l’évaluation des risques.
On peut dire que toutes les données sont des données sur le crédit, mais il manque encore la façon de les utiliser.
Douglas Merrill, fondateur de ZestFinance et ancien directeur des systèmes d’informations chez Google, 2012
prédire-létat-de-santé-à-partir-des-données-client »>Prédire l’état de santé à partir des données client
Les entreprises de données et les assureurs travaillent sur des programmes qui utilisent les informations sur la vie quotidienne des consommateurs pour prédire leurs risques de santé. Par exemple, l’assureur Aviva, en coopération avec la société de conseil Deloitte, a utilisé des données clients achetées à un courtier en données et habituellement utilisées pour le marketing, pour prédire les risques de santé individuels (comme le diabète, le cancer, l’hypertension et la dépression) de 60 000 personnes souhaitant souscrire une assurance.
La société de conseil McKinsey a aidé à prédire les coûts hospitaliers de patients en se basant sur les données clients d’une « grande compagnie d’assurance » santé américaine. En utilisant les informations concernant la démographie, la structure familiale, les achats, la possession d’une voiture et d’autres données, McKinsey a déclaré que ces « renseignements peuvent aider à identifier des sous-groupes stratégiques de patients avant que des périodes de coûts élevés ne surviennent ».
L’entreprise d’analyse santé GNS Healthcare a aussi calculé les risques individuels de santé de patients à partir d’un large champ de données tel que la génétique, les dossiers médicaux, les analyses de laboratoire, les appareils de santé mobiles et le comportement du consommateur. Les sociétés partenaires des assureurs tels que Aetna donnent une note qui identifie « les personnes susceptibles de subir une opération » et proposent de prédire l’évolution de la maladie et les résultats des interventions. D’après un rapport sectoriel, l’entreprise « classe les patients suivant le retour sur investissement » que l’assureur peut espérer s’il les cible pour des interventions particulières.
LexisNexis Risk Solutions, à la fois, un important courtier en données et une société d’analyse de risque, fournit un produit d’évaluation de santé qui calcule les risques médicaux ainsi que les frais de santé attendus individuellement, en se basant sur une importante quantité de données consommateurs, incluant les achats.
Collecte et utilisation massives de données client
Les plus importantes plates-formes connectées d’aujourd’hui, Google et Facebook en premier lieu, ont des informations détaillées sur la vie quotidienne de milliards de personnes dans le monde. Ils sont les plus visibles, les plus envahissants et, hormis les entreprises de renseignement, les publicitaires en ligne et les services de détection des fraudes numériques, peut-être les acteurs les plus avancés de l’industrie de l’analyse et des données personnelles. Beaucoup d’autres agissent en coulisse et hors de vue du public.
On va vraiment très loin. D’un autre côté, je me demande qu’elle peut être la fiabilité de ces données basées sur des algorithmes parfois assez étranges…
Je suppose que toutes nos données sont maintenant cotées en bourse ?
Et le jour où ces entreprises vont commencer à se racheter entre elles, bonjour les fichiers croisés !
Pour ne pas être tracé, il ne faut déjà pas de compte personnel (Messagerie, Facebook, etc.)… ce qui n’est pas évident ni toujours possible (comptes bancaires, impôts). Pour que la mémoire de l’ordi ne puisse pas être examinée, Linux en compte invité (aucune donnée ne subsiste après sortie de session, le compte invité étant créé dans le /tmp et non dans le /home), utilisation de Tor ou d’un VPN pour compliquer la détection de l’IP, Si on veut en outre qu’aucune donnée perso ne soit stockée sur le disque dur, alors boot sur un périphérique externe (clé, live CD). Tout ça ne présente pas de difficulté technique mais pas mal de contraintes. Pour tout dire, c’est très chiant et ne se justifie que pour des activités (illégales) ponctuelles. Si on a de la place, on peut aussi avoir un PC pour utilisation en local (stockage et traitement de données), non connecté à Internet et un autre utilisé ponctuellement pour des opération de communication. C’est un mode de vie laborieux.
si nous sommes tracé, c’est dans un but et un seul, nous faire consommer!! alors la seule solution est d’avoir des règles de consommation au niveau individuel! Et vivre sobrement avant tout !
Par ailleurs, il faut bien financer l’internet, car aujourd’hui tout le monde trouve normal que cela soit gratuit, or il n’y a pas si longtemps pour trouver des info ou voir des vidéo il fallait payer pour tout !!
Alors soyons heureux qu’une partie des internautes « consomment »
Eh bien qu´ils se mijotent un poule au pôt avec mes données. Je les emmerdent.
Ils peuvent contrôller oui, mais pas influencer. Ok, certains si, on peut les influencer.






On va vraiment très loin. D’un autre côté, je me demande qu’elle peut être la fiabilité de ces données basées sur des algorithmes parfois assez étranges…
Je suppose que toutes nos données sont maintenant cotées en bourse ?
Et le jour où ces entreprises vont commencer à se racheter entre elles, bonjour les fichiers croisés !
D’où aussi l’intérêt de ne pas (ou plus) souscrire aux cartes de fidélités qui tracent davantage les habitudes de consommation du client.
Côté internet, une solution pour ne pas être tracé : pirater la box du voisin ou lui demander le partage de connexion moyennant finances.
Pour ne pas être tracé, il ne faut déjà pas de compte personnel (Messagerie, Facebook, etc.)… ce qui n’est pas évident ni toujours possible (comptes bancaires, impôts). Pour que la mémoire de l’ordi ne puisse pas être examinée, Linux en compte invité (aucune donnée ne subsiste après sortie de session, le compte invité étant créé dans le /tmp et non dans le /home), utilisation de Tor ou d’un VPN pour compliquer la détection de l’IP, Si on veut en outre qu’aucune donnée perso ne soit stockée sur le disque dur, alors boot sur un périphérique externe (clé, live CD). Tout ça ne présente pas de difficulté technique mais pas mal de contraintes. Pour tout dire, c’est très chiant et ne se justifie que pour des activités (illégales) ponctuelles. Si on a de la place, on peut aussi avoir un PC pour utilisation en local (stockage et traitement de données), non connecté à Internet et un autre utilisé ponctuellement pour des opération de communication. C’est un mode de vie laborieux.
si nous sommes tracé, c’est dans un but et un seul, nous faire consommer!! alors la seule solution est d’avoir des règles de consommation au niveau individuel! Et vivre sobrement avant tout !
Par ailleurs, il faut bien financer l’internet, car aujourd’hui tout le monde trouve normal que cela soit gratuit, or il n’y a pas si longtemps pour trouver des info ou voir des vidéo il fallait payer pour tout !!
Alors soyons heureux qu’une partie des internautes « consomment »
Le « big data » ou la recette secrète du succès d’Emmanuel Macron ?
https://www.crashdebug.fr/informatik/93-securite/13568-le-big-data-ou-la-recette-secrete-du-succes-d-emmanuel-macron
Bonne soirée, ; )
f.
Eh bien qu´ils se mijotent un poule au pôt avec mes données. Je les emmerdent.
Ils peuvent contrôller oui, mais pas influencer. Ok, certains si, on peut les influencer.
Les connries comme twitter, facebook, etc… je n´en voulais jamais, et n´en voudrais non plus à n´importe quel prix. Rien qu´a y penser a la conversation de zuckerberg à ses débuts.
La version française, c´est mal traduit, cela devrait se dire « ces idiots », et non « putains d´idiots »
http://www.konbini.com/fr/tendances-2/naissance-de-facebook-les-messages-prives-de-mark-zuckerberg/
Une version allemande d´un site le décrit bien. Traduisez vous-même avec gogol et laissez vous surprendre.
http://www.cyber-magazin.de/2010/05/facebook-grunder-diese-vollidioten-vertrauen-mir/